Analytics Service¶
1. Introduction¶
IoT is one of the main pillars of the digitization revolution. Utilizing the data captured from a plethora of sensors connected with the IOT platform, applying statistics, machine learning and analytic approaches to the data to solve critical business problems is now an emerging practice. Now day by day Analytics on time series data along with image and video processing is becoming important for IIoT in the era of Industry 4.0 TCUP Analytics Service provides a natural interface to the data scientists to explore and experiment with the data stored in TCUP platform. It also provides some basic support for image and video processing as well. The data captured in TCUP is analyzed by Analytics Service where the modules are designed in a manner so that it can be used by both data scientists and data engineers seamlessly. Data scientists can choose to add new modules or re-use the default ones provided in TCUP Analytics. This module supports the following analytics algorithms:
Descriptive Analytics
Diagnostic Analytics
Predictive Analytics
Prognostic Analytics
1.1 Intended Audience¶
The intended audience of this document are the data scientists and the data engineers who wants an overview of TCUP Analytics Service. After reading this document the user will understand the capability of TCUP Analytics in IoT platform.
2. Key Concepts¶
In order to use Analytics Service, a user needs to understand some of the basic concepts and building blocks of Analytics. Please refer to the following section for the concepts:
2.1 Data Preparation¶
Availability of a large number of sensors that are connected with devices and linked with the internet has increased the volume of time series data captured for performing analytics. In Data Science (DS), data preparation algorithms are often referred to as datafication and data quantification. These data are mostly universal in nature.
2.2 Descriptive Analytics¶
This refers to the type of data analytics that typically uses statistics to describe the captured data to gain information or for other useful purposes.
2.3 Diagnostic Analytics¶
Diagnostic Analytics is a form of advanced analytics which examines data or content to answer the question “Why did it happen?” This helps to identify trends, thresholds, anomalies and other metrics that lead to the subsequent question of why something happened.
2.4 Predictive Analytics¶
Refers to the type of data analytics that makes predictions about unknown future events and discloses the reasons behind them, typically by advanced analytics.
2.5 Prognostic Analytics¶
Refers to the type of data analytics that optimizes indications and recommends actions for smart decision-making.
3. Functional Capabilities¶
The list of algorithms can assist the users in the following ways: - Prepare the data for applying Machine Learning (ML) modules to the input time series data. - Noise removal on the input time series. - Visualization of data distribution of a sensor data (Histogram) - Visualization of the relationship among the input sensors (using Heat map both 2D and 3D) - Visualization of a high dimensional data in best separated 2D representation using automated parameter tuned t-Stochastic Neighbor Estimation (tSNE) and UMAP. - Diagnostic modules can be used to identify whether there is some abnormality in the data using K-means, and distance/divergence modules like Bhattacharyya distance (BD) and Kullback–Leibler divergence (KLD). - Diagnostic modules can also help to classify AND/OR cluster the input data depending on the availability of ground truth. - Predictive modules can be used to predict:
Any sensor data using rest of the sensors.
Predict the value of a sensor observation at a future point of time.
Prognostic modules can be used to identify the root cause of failure.
Prognostic module can also be used to plan the optimal time of tool replacement.
Similarity of time series data captured from plethora of sensors.
Controllable input feature range prediction for a target output
Unsupervised approaches for machine fault detection.
4. Purpose/Usage¶
This system can be used by both data scientists and data engineers:
Data Scientists
Data scientists prefers to write their own codes and analyze the results. Majority of the effort of data scientists are spent on data preparation and data ingestion. TCUP Analytics service helps to:
Seamlessly make the data available by ease of access, for example from Data Lake Service.
Pre-process the data using the algorithms.
Data scientists also prefers to visualize that data/model/performance in different stages of analysis. To address this:
The proposed solution is equipped with histogram to do initial visual analytics on the input data.
Heat map helps to understand the relationship and dependency among sensors.
tSNE’ and ‘UMAP’ allows to visualize multi-dimensional time series data. ‘tSNE’ and ‘UMAP’ have been proven to be a better dimension reduction tool as well that can be used to visualize the data in two or three dimension, reduce data dimensions, feature extraction in case of traditional machine learning.
Visualize the confusion matrix in case of classification/clustering.
TCUP Analytics Service also provides data scientists with the flexibility to write their own codes AND/OR use set of algorithms provided by the proposed solution by just importing the libraries.
Data Engineers
The data engineers would also be greatly benefited by using this tool as they can:
Play with various algorithms to accomplish a particular machine learning for example clustering, classification etc.
Get the best kernel and hyper parameters even without having detailed knowledge of machine learning or domain, as the proposed solution can recommend the best hyper parameters and kernels.
Easily use the set of algorithms which would reduce the time to learn the algorithms and develop code.
5. Examples¶
Use Case: 1¶
Let us consider a use case where the user is getting the data from a Friction Stir Wielding (FSW) machine. The input data for analytics obtained from the different sensors attached with the FSW machine contains the power, torque, force applied, rotation per minute (RPM) of the tool and the horizontal velocity of the materials to be wielded.
The intended goal of the project is to predict the Ultimate Tensile Strength (UTS) of the materials produced by the FSW machine. It is difficult for the user to visualize the data as the input data is of a very high dimension, to simplify this the steps to be followed are:
tSNE and UMAP can be applied initially to visualize the data in 2D or 3D.
Predictive algorithms can be applied on an annotated data set to construct the model for prediction.
Eventually that model can be used by the model execution module of predictive analytics (like Support Vector Regression/ Random Forest Regression/ Long Short-Term Memory) to predict the UTS on real time.
Use Case: 2¶
LLet us consider the case of a steel manufacturer who wants to automate failure or abnormal behavior detection of their coolant pump. Input to the system is the telemetry data obtained from plethora of sensors attached with the four pumps of the system. Each pump has two sensors to sense the rotation per minute (RPM) and the fluid flow rate.
Solution:
Following steps are followed to obtain the solution:
In the first step a sliding window is obtained to capture the temporal feature of the Time Series (TS) data
Apply LSTM encoder decoder to get an embedding of the TS data in a higher dimension
UMAP is applied on the above-mentioned data to reduce the dimensions to two dimensions
Clustered the 2D data using a density-based clustering algorithm.
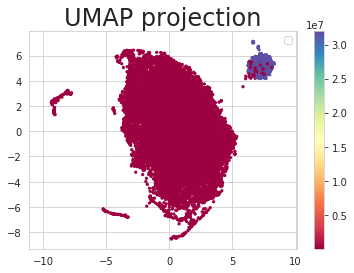
Use case: 3¶
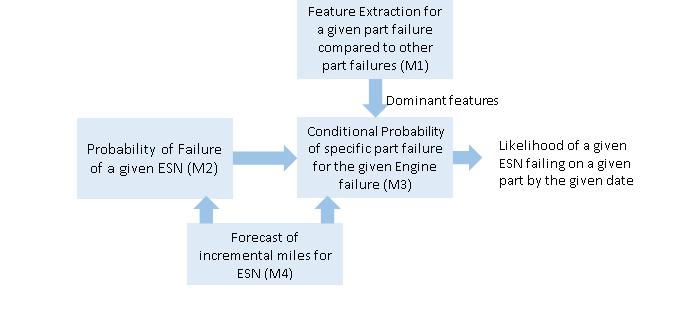
Let us consider the case of a global engine manufacturer who wants to develop a predictive maintenance for their engines. Analytics is used to (i) identify the features with highest importance in classification, (ii) create a regression model to predict the mileage at a future time, (iii) Find the failure probability of the engines. Data description: The data of failure and claim records of nearly 9000 engines and each have a record of almost 10-15 years. Total volume of the record is nearly 50 GB.
Solution: Following are the solution steps: 1. In the step one Model 1 (M1) is used to list the interpretable features using one module of TCUP 12 Analytics, namely “feature recommender” 2. Then Model 2 (M2) is created to find the health index of each machine part 3. Model 3 (M3) is used to predict the failure probability of the engine and 4. Model 4 (M4) is used to predict the mileage at a future time.
Here is the schematic diagram of the proposed solution
Use case: 4¶
Let us consider the use case for a global steel manufacturer who wants to identify wielding defects from wielding images. Wielding is done only on a small portion which is visible only on specific part of the image.
Data description: There would be only a few sets of annotated faulty and non-faulty images. There might be class imbalance i.e. the number of faulty images would be much less than non-faulty images.
Solution: Following are the solution steps: 1. Use TCUP’s data augmentation techniques to increase number of samples. 2. Same data augmentation can be applied selectively on only one class to resolve the imbalance issue. 3. Visualize the original and augmented images using TCUP’s visualize. 4. Train Transfer-learning based object detection algorithm on NVIDIA GPU. 5. Evaluate the model once training completes. 6. Visualize the inference quality using TCUP’s visualizer. 7. Compress or prune it for edge deployment.
Use case: 5¶
Let us consider a use case where the user is getting the data from the plethora of sensors attached with a car engine. Normally any engine manufacturer consists of the records of thousands of engines produced over many years. The first thing user want is to evaluate the quality of data. One module identifies the data statistics. A similarity among sensors is identified among the sensors. Then a non-linear algorithm is applied to populate the missing data. None of the data is annotated and hence an unsupervised algorithm is applied on it to (i) find the RUL of each engine and (ii) predict a suitable range of controllable parameters so that user can get the desired output.
Data description: The data consists of the telemetry data obtained from the sensors attached with the car engine. Each running engine transmits the data at every 10 minutes interval. Number of such engines are nearly 10,000.
Solution: Following are the solution steps:
Populate the missing data using missing data imputation module of TCUP 12 Analytics
Identify the root cause analysis
Identify the Health Index (HI) of each engine
Identify the remaining useful life (RUL) for each engine.
6. Reference Document¶
Please refer to the following document for more details about this service:
API Guide